Du traitement distribué de données sur Hadoop en utilisant R
- 5 minsDans cet article, j’explique comment utiliser R (ou tout autre programme que Java) pour faire du traitement distribué de données sur Hadoop. Pour moi qui n’ai jamais appris Java, cette idée est simplement géniale. La façon la plus simple d’y arriver, c’est avec l’API Streaming, lequel interprète des instructions de type Map et Reduce (séparément, comme nous le verrons) transmises dans un langage autre que Java (par exemple Ruby, Shell, etc.) et se charge de les exécuter comme une tâche typique MapReduce.
Ensemble nous allons écrire un petit programme Wordcount (pour compter les occurrences de mots dans une phrase) et utiliser l’API Streaming pour traiter la tâche de façon distribuée.
Pour commencer, nous avons besoin d’installer R sur le serveur ou la machine hôte du cluster, puisque c’est de R qu’il s’agit. Pour ça, exécuter (en tant que super utilisateur root) :
yum install -y RL’API Streaming
Comme je l’ai expliqué, Streaming se charge de traduire des instructions écrites dans un langage autre que Java, en une tâche typique MapReduce. L’API, disponible sur toutes les installations d’Hadoop, requiert un script au stade Map, un script au stade Reduce, un fichier de données à traiter, le nombre de fragmentations désirées pour la tâche, et un fichier pour stocker le rendu du traitement.
Dans le cas de notre exemple, avec Wordcount, voici à quoi ressemble la commande :
hadoop jar ${HADOOP_PREFIX}/share/hadoop/tools/lib/hadoop-streaming*.jar \
-input /wc.txt \
-output /wc-r.result \
-mapper 'cat' \
-reducer /wc.r \
-numReduceTasks 4 \
-file wc.r && \
hadoop fs -cat /wc-r.result/*${HADOOP_PREFIX}/share/hadoop/tools/lib/hadoop-streaming*.jarindique l’emplacement du jar de Streaming ; j’utilise * dans <hadoop-streaming*.jar> pour rester neutre vis-à-vis de la version d’Hadoop que vous pourriez utiliserinput /wc.txt: input spécifie l’emplacement du fichier de données (ici wc.txt) ; il faut noter que cet emplacement se réfère à HDFS, le système de stockage distribué d’Hadoop. Les données doivent donc être préalablement copiées sur HDFSoutput /wc-r.result: output indique le fichier d’enregistrement du rendu de traitement (ici wc-r.result), toujours dans HDFS. Ce fichier sera créé lors de l’exécution de la tâchemapper 'cat': mapper spécifie le script du stade Map. Ici, la commande Shellcat(affiche le contenu de fichier texte), permet de faire passer nos données au stade Reduce sans modificationreducer /wc.r: reducer spécifie le script du stade Reduce. Ici, wc.r, indique le nom du fichier du script R pour wordcount. Nous verrons par la suite comment le créer.numReduceTasks 4: indique 4 fragmentations au stade Reducefile wc.r: l’argument file spécifie l’emplacement du fichier de script utilisé au stade Reduce. A supposer que nous ayons specifié un script R au stade Map, par exemple le fichier wc_map.r, il aurait fallu mettrefile wc.r wc_map.r. Notez que ces emplacements se réfèrent au stockage du serveur ou la machine hôte, et non à HDFS.
Les données
Nous créons notre fichier de données sur HDFS, en exécutant :
echo "This is an exemple of wordcount. This is an exemple of wordcount." | hadoop fs -appendToFile - /wc.txtNous allons donc appliquer Wordcount sur le court paraphrage «This is an exemple of wordcount. This is an exemple of wordcount.».
Algorithme R pour Wordcount
Notre script R ressemble à ceci :
#!/usr/bin/env Rscript
f <- file("stdin",open = 'r')
tmp1 = readLines(f,warn = F)
write.table(table(factor(unlist(strsplit(tmp1,"\s|\s+")))),quote = FALSE,row.names = FALSE,col.names = FALSE,sep = "\t")
close(f)
#ENDNous avons besoin de créer le fichier
Traitement distribué
Pour procéder au traitement des données, exécuter :
hadoop jar ${HADOOP_PREFIX}/share/hadoop/tools/lib/hadoop-streaming*.jar \
-input /wc.txt \
-output /wc-r.result \
-mapper 'cat' \
-reducer /wc.r \
-numReduceTasks 4 \
-file wc.rRésultats
Le rendu du traitement sera enregistré dans le fichier
hadoop fs -cat /wc-r.result/*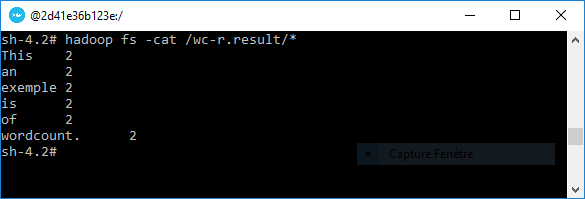
Résultats avec Java
Une façon de vérifier que le script R fait du bon travail, est de faire la même démarche en utilisant cette fois-ci le jar de Wordcount, fourni avec toutes les installations Apache Hadoop. Pour ce faire, exécuter ceci :
hadoop jar ${HADOOP_PREFIX}/share/hadoop/mapreduce/hadoop-mapreduce-example*.jar wordcount /wc.txt /wc-java.result && \
hadoop fs -cat /wc-java.result/*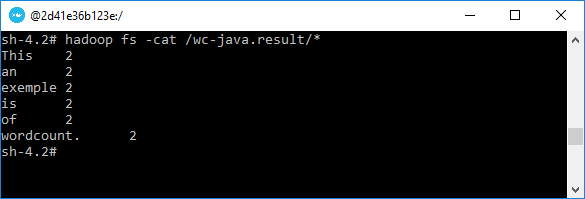
Voila ! Ce sera tout pour cet article. Ensemble, nous avons vu comment mettre en œuvre du traitement distribué de données sur Hadoop à partir de R :
- Comment utiliser l’API Streaming d’Apache Hadoop
- Comment créer, éditer et lire un fichier texte sur HDFS
- Comment créer une fonction R pour compter les occurrences des mots d’une phrase (wordcount)
Merci pour cette lecture!